
* 운영 서버 스펙: Cent OS7, RAM: 16GB, GPU X
* Python: v3.13
* Flask: 3.1.0
* Langchain: 0.3.25
* ollama: 0.4.8
1. 서론
이전 포스팅: https://hand-mk.tistory.com/19
[Ollama] Ollama 사용기 (1)
* OS: Windows 11 pro* RAM: 64GB* CPU: Intel(R) Core(TM) i7-14700* GPU: 내장 그래픽 1. 서론회사 백오피스 서비스 개발에서 항공 전문에 대한 AI 해석 및 요약 기능 구현 담당을 맡았다..!내 주전공은 데이터 사이
hand-mk.tistory.com
회사 백오피스 서비스 개발에서 항공 전문에 대한 AI 해석 및 요약 기능 구현 담당을 맡았다. 항공 전문을 AI 가 이해하기 쉽게 한국어로 해석하고 요약하는데 있어, 가장 어려운 점은 AI 가 항공 전문에서 사용하는 코드(ICAO 공항 코드, 날씨코드 등) 를 모른다는 것이다. 물론 OpenAPI 나 Gemini 클라우드 환경에서 전문넣고 해석해 달라고 하면 웹 전반을 RAG 화 하여 사용하기 때문에 성능이 괜찮지만, 본 AI 모델은 온프레미스 서버에 설치하고 사용해야 하기 때문에 어려움을 겪었다. 그래서 필자가 생각한 방법은 어느정도 해석에 필요한 핵심 단어들을 전처리하고 이를 Ollama 모델을 통해 문장화 시키는 방식이다.
어찌저찌 ICAO, 항공기상업무지침 pdf 등 디코딩 문서를 확인하여 파서 로직을 구현하여 이제 RESTful 하게 만드는 단계이다. 이에 대해 기술한 내용이다.
2. 본론
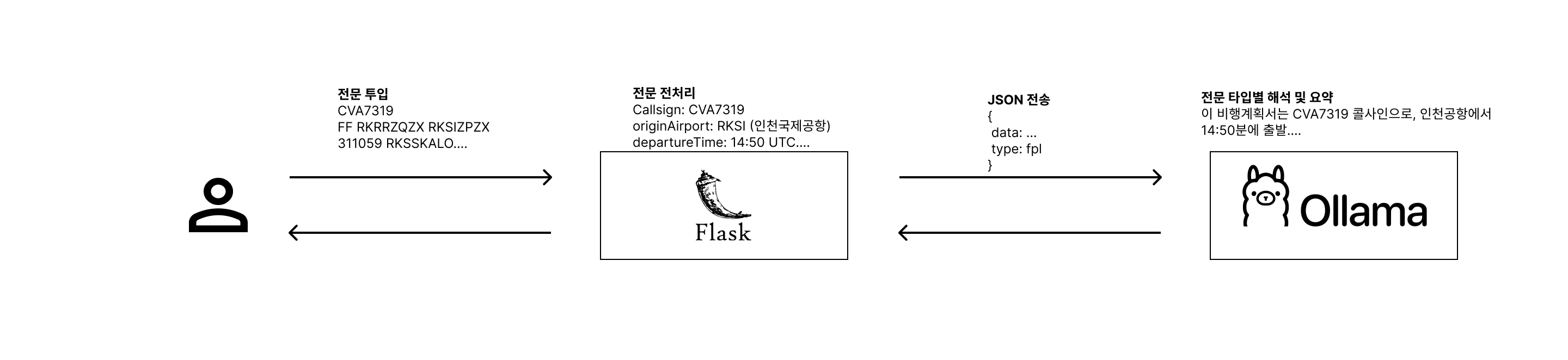
기본적으로 사용자 > `Python (Flask)` > `AI (Ollama)` > 의 파이프라인으로 구성하였다. Flask 에서 AI 요청 및 응답을 받기 위해선 Ollama 를 Docker Container 으로 구동시켜야 한다.
2.1. 운영 서버 Ollama Docker Container 구동
Docker Image 는 Docker Hub 공식 이미지를 사용하였다.
https://hub.docker.com/r/ollama/ollama
ollama/ollama - Docker Image
hub.docker.com
docker-compose.yml
services:
ollama:
volumes:
- ollama:/root/.ollama
ports:
- 11434:11434
container_name: ollama
image: ollama/ollama
volumes:
ollama:
external: true
name: ollama
2.2. Python 에서 Ollama 호출
ollama 는 python 과의 통합사용을 적극 장려하고 있어, 관련 패키지를 공유하고 있고 이에 대한 내용은 공식 organization 에서 확인 가능하다.
https://github.com/ollama/ollama-python
GitHub - ollama/ollama-python: Ollama Python library
Ollama Python library. Contribute to ollama/ollama-python development by creating an account on GitHub.
github.com
Python 에서 Ollama 서버를 호출하고 제어하려면 `ollama`, `ollama-langchain` 패키지를 설치해야 한다.
pip install langchain-ollama
pip install ollama
이후 인스턴스를 생성하여 제어 및 호출이 가능하다.
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="exaone3.5:7.8b",
base_url="http://ollama:11434" # 동일 Docker network 상에서 구동될 예정
)
공식문서 상에서는 ollama 패키지의 `chat` 을 통해 생성했다.
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='gemma3', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
# or access fields directly from the response object
print(response.message.content)
이 방법도 '가능' 하다. 하지만 프롬프트나 vectorDB 를 chain 형식으로 묶어 호출하지 못하고 직접 개발자가 구현해야 한다.
비행계획서 (FPL) 전문에 대한 질문 프롬프트를 다음과 같이 작성했을 때
FPL_TEMPLATE = """
아래는 ICAO 비행계획서 최초 제출 시 전문에 들어간 정보야.
콜사인 : {aircraft_id},
비행 일자 : {flight_date},
출발 공항 : {departure_airport},
출발 예정 시간 : {departure_time},
도착 공항 : {arrival_airport},
도착 예정 시간 : {arrival_time},
대체 공항 : {alternate_airport},
출발 공항 부터 도착 공항까지 소요 시간 : {duration_time},
비행 경로 : {flight_route},
비행 종류 : {flight_method}
'{flight_date}, {departure_airport}에서 {arrival_airport}으로 운행 예정인 {aircraft_id}편은 {flight_method}으로, 출발 예정 시각은 {departure_time}이고, 도착 예정 시각은 {arrival_time}이며, 비행 경로는 {flight_route}이고, 대체 공항은 {alternate_airport}로 지정 돼 있습니다.'
위 정보들만 전부 사용해서 최초 제출 비행 계획서를 위 예시대로 한국어로 한문장으로 요약해줘.
경로는 누락되면 안돼.
"""
`langchain` 을 사용할 경우 템플릿에 변수를 자동으로 넣은 다음, `|` 로 추가하여 응답을 요청하면 된다.
# 전문 전처리 함수
result = fpl_split(code)
summary_template = FPL_TEMPLATE
summary_kwargs = {
"aircraft_id": result.get("aircraft_id", ""),
"flight_date": result.get("flight_date", ""),
"departure_airport": result.get("departure_airport", ""),
"departure_time": result.get("departure_time", ""),
"arrival_airport": result.get("arrival_airport", ""),
"arrival_time": result.get("arrival_time", ""),
"alternate_airport": result.get("alternate_airport", ""),
"duration_time": result.get("duration", ""),
"flight_route": result.get("flight_route", ""),
"flight_method": result.get("flight_method", ""),
}
# 프롬프트에 자동으로 변수 기입
prompt = ChatPromptTemplate.from_template(
summary_template
)
chain = prompt | llm # 프롬프트 체이닝
response = chain.invoke(summary_kwargs)
만약 `chat` 으로 생성할 경우에는 변수를 직접 지정하고, 응답 결과에 대해서 포맷팅 또한 이후 전처리 과정을 추가해야 한다.
# 사용자가 직접 문자열을 조립해야 함
formatted_prompt = summary_template.format(
aircraft_id=data['id'],
flight_route=data['route'],
... # 모든 변수를 일일이 나열
)
ollama.chat(messages=[{'role': 'user', 'content': formatted_prompt}])
# 이후 '네 요약해드리겠습니다.' 와 같은 불필요한 응답 값 전처리 해야함.
모델 인스턴스를 기반으로 전문 전처리 함수를 호출 > 해석에 필요한 전처리 함수로 AI 해석 및 요약 전체 코드이다.
def fpl_llm(code: str):
print("[fpl_llm] model called!")
content = fpl_extract_message(code)
message_type = extract_message_type(content)
print(f"[fpl_llm] message type : {message_type}")
# 비행 계획서
if message_type == "FPL":
result = fpl_split(code)
summary_template = FPL_TEMPLATE
summary_kwargs = {
"aircraft_id": result.get("aircraft_id", ""),
"flight_date": result.get("flight_date", ""),
"departure_airport": result.get("departure_airport", ""),
"departure_time": result.get("departure_time", ""),
"arrival_airport": result.get("arrival_airport", ""),
"arrival_time": result.get("arrival_time", ""),
"alternate_airport": result.get("alternate_airport", ""),
"duration_time": result.get("duration", ""),
"flight_route": result.get("flight_route", ""),
"flight_method": result.get("flight_method", ""),
}
# 일정 변경 계획서
elif message_type == "CHG":
result = chg_split(code)
summary_template = CHG_TEMPLATE
summary_kwargs = {
"aircraft_id": result.get("aircraft_id", ""),
"flight_date": result.get("flight_date", ""),
"departure_airport": result.get("departure_airport", ""),
"departure_time": result.get("departure_time", ""),
"arrival_airport": result.get("arrival_airport", ""),
"changed_callsign": result.get("changed_callsign", ""),
"changed_flight_method": result.get("changed_flight_method", ""),
"changed_flight_num": result.get("changed_flight_num", ""),
"changed_flight_equip": result.get("changed_flight_equip", ""),
"changed_dep_airport": result.get("changed_dep_airport", ""),
"changed_dep_time": result.get("changed_dep_time", ""),
"changed_route": result.get("changed_route", ""),
"changed_alternative_airport": result.get("changed_alternative_airport", ""),
"changed_arr_airport": result.get("changed_arr_airport", ""),
"changed_arr_time": result.get("changed_arr_time", ""),
"changed_dof": result.get("changed_dof", "")
}
# 지연 계획서
elif message_type == "DLA":
result = dla_split(code)
summary_template = DLA_TEMPLATE
summary_kwargs = {
"flight_date": result.get("flight_date", ""),
"aircraft_id": result.get("aircraft_id", ""),
"departure_airport": result.get("departure_airport", ""),
"arrival_airport": result.get("arrival_airport", ""),
"changed_time": result.get("changed_time", ""),
}
# 취소 계획서
elif message_type == "CNL":
result = cnl_split(code)
summary_template = CNL_TEMPLATE
summary_kwargs = {
"flight_date": result.get("flight_date", ""),
"aircraft_id": result.get("aircraft_id", ""),
"departure_airport": result.get("departure_airport", ""),
"arrival_airport": result.get("arrival_airport", ""),
"departure_time": result.get("departure_time", ""),
}
# 출발 계획서
elif message_type == "DEP":
result = dep_split(code)
summary_template = DEP_TEMPLATE
summary_kwargs = {
"flight_date": result.get("flight_date", ""),
"aircraft_id": result.get("aircraft_id", ""),
"departure_airport": result.get("departure_airport", ""),
"arrival_airport": result.get("arrival_airport", ""),
"departure_time": result.get("departure_time", ""),
}
# 도착 계획서
else:
result = arr_split(code)
summary_template = ARR_TEMPLATE
summary_kwargs = {
"aircraft_id": result.get("aircraft_id", ""),
"departure_time": result.get("departure_time", ""),
"departure_airport": result.get("departure_airport", ""),
"arrival_airport": result.get("arrival_airport", ""),
"arrive_time": result.get("arrive_time", ""),
}
print(f"[fpl_llm] result : {result}")
prompt = ChatPromptTemplate.from_template(
summary_template
)
chain = prompt | llm
response = chain.invoke(summary_kwargs)
# 응답 값 DB 저장
try:
orm = SessionLocal()
new_fpl_rst = FplAiResult(code, response)
orm.add(new_fpl_rst)
orm.commit()
print(f"[fpl_llm] saved result successfully!")
except Exception as e:
orm.rollback()
print(f"[fpl_llm] fail to save result! cause : {str(e)}")
finally:
orm.close()
return success_response(response)
이 `fpl_llm` 을 /fpl 엔드포인트에서 호출되게끔 flask 라우터를 설정하여 Ollama 를 호출 할 수 있게 하였다.
이하 항공 고시보 (Notam), 날씨 (Metar, Taf) 또한 동일한 파이프라인으로 구성하였다.
fpl_model = api.model('FplModel', {
'fpl': fields.String(required=True, description='Fpl Contents'),
})
@api.route("/fpl")
class Fpl(Resource):
@api.expect(fpl_model)
def post(self):
body = request.get_json()
code = body.get("fpl")
return fpl_llm(code)


배포 서버(CentOS 7) 기준 응답 테스트시 다음과 같이 속도가 나왔다. 회사 선배들을 대상으로 실제 단위 테스트에서 100개의 전문을 테스트 했을 때 약 65개의 응답에 대해 100% 해석 만족도가 있다고 답변했고, 나머지 응답에 대해서 약간의 이상치(한국어랑 영어 섞임)가 보였다.
[GIN] 2025/05/26 - 03:00:55 | 200 | 58.96749926s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/05/26 - 04:57:22 | 200 | 37.214435283s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/05/26 - 05:00:29 | 200 | 19.606718973s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/05/26 - 05:11:35 | 200 | 12.929574367s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/05/26 - 05:01:36 | 200 | 12.077014236s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/05/26 - 05:03:29 | 200 | 10.600447629s | 172.21.0.7 | POST "/api/generate"

2.3. vectorDB 화
단위 테스트를 했더니 필자가 그냥 비슷한 전문을 계속 넣었을 때랑 부끄러울 정도로 응답 속도 차이가 많이 났다..! 중간에 뻗어버리는 경우도 생겼다. 무엇이 문제였을까 곰곰히 생각해보다가, 필자의 디코딩이 문제였지 않았나 생각이 들었다.
이전에는 ICAO 공항코드, 날씨(구름양, 강수량등) 코드와 같은 룩업 데이터를 txt 파일에 수집하였다. 이를 파싱시 line 으로 읽어 한국 라벨값을 찾는 방식이였다.
이전방식
airport_codes.txt (ICAO 공항코드) 약 5100개
LECO: 아코루냐 공항
EKYT: 올보르 공항
EKAH: 오르후스 공항
BGAA: 아시아앗 공항
HAJM: 아바 세구드 공항
HADR: 아바 테나 데자즈마흐 일마 국제공항
OIAA: 아바단 공항
NGAB: 아바이앙 공항
UNAA: 아바칸 공항
CYXX: 애버츠퍼드 국제공항
DAOB: 압델하피드 부수프 부 체키프 공항
RKRR: 인천비행정보구역
WARA: 압둘 라흐만 살레 공항
HCMR: 압둘라히 유수프 국제공항
FTTC: 아베셰 공항
HTZA: 아베이드 아마니 카루메 국제공항
MUSC: 아벨 산타마리아 공항
NGTB: 아베마마 아톨 공항
EGPD: 애버딘 국제공항
KABR: 애버딘 지역 공항
OEAB: 아바 공항
KABI: 애빌린 지역 공항
MMCS: 아브라함 곤잘레스 국제 공항
KSPI: 에이브러햄 링컨 캐피털 공항
LIBP: 아브루초 공항
OMAA: 아부다비 국제공항
OIBA: 아부무사 공항
HEBL: 아부심벨 공항
KARA: 아카디아나 지역공항
SKAD: 아칸디 알시데스 페르난데스 공항
MMAA: 아카풀코 알바레스 국제공항
DGAA: 아크라 코토카 국제공항
WAHS: 아흐마드 야니 국제공항def lookup_code(key, file):
with open(file, encoding="UTF-8") as f:
for line in f:
if line.startswith(f"{key}:"):
print(f"[lookup_code] found code! : {key}")
return line.split(":", 1)[1].strip()
print(f"[lookup_code] not found code! : {key}")
return None
공항코드 일부분만 발취하였으나, 얼추 세어보니 전문 해석용 룩업 데이터가 모두 취합시 약 7만건 정도 됐다.
이들을 모두 vectorDB 화 하여, 전문 타입별로 해석시 임베딩 하는 방법으로 변경해 보았다.
공항 ICAO 코드 vectorDB화 (2분 46초 소요)
import os
from langchain_community.document_loaders import TextLoader
from langchain_core.documents import Document
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
def create_airport_vectordb():
# 데이터 로드 (airport_codes.txt)
file_path = "airport_codes.txt"
documents = []
with open(file_path, "r", encoding="UTF-8") as f:
for line in f:
if ":" in line:
code, name = line.split(":", 1)
# 텍스트는 공항 이름으로, 메타데이터에 코드를 저장
doc = Document(
page_content=f"{code.strip()}: {name.strip()}",
metadata={"code": code.strip(), "name": name.strip()}
)
documents.append(doc)
# 임베딩 모델 설정 (Ollama 사용)
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# VectorDB 생성 및 로컬 저장
vector_db = Chroma.from_documents(
documents=documents,
embedding=embeddings,
persist_directory="./airport_db" # 로컬 폴더에 DB 저장
)
print("Airport VectorDB 구축 완료!")
return vector_db
기존의 라인으로 읽던 방식을 생성한 vectorDB 기반으로 데이터 값을 추론할 수 있게끔 하여, AI 에게 던져준다.
def lookup_airport(code):
# 기존의 파일 읽기 방식(lookup_code)을 VectorDB 방식으로 대체
# VectorDB에서 유사도 기반 검색
results = vector_db.similarity_search(code, k=1)
if results:
# 검색된 결과의 메타데이터에서 공항명을 반환
return results[0].metadata["name"]
return code # 못 찾으면 원래 코드라도 반환
테스트 했을 때 확실히 응답 속도에서 향상된 모습을 확인 할 수 있었다.
[GIN] 2025/06/25 - 14:22:15 | 200 | 15.423s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/06/25 - 14:25:42 | 200 | 12.112s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/06/25 - 14:30:08 | 200 | 9.876s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/06/25 - 14:35:12 | 200 | 8.543s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/06/25 - 14:42:55 | 200 | 7.210s | 172.21.0.7 | POST "/api/generate"
[GIN] 2025/06/25 - 14:50:33 | 200 | 6.836s | 172.21.0.7 | POST "/api/generate"
3. 아쉬운 점
첫번째 아쉬운 점은 파인튜닝을 못해본 것이다.
원래 LLM 모델을 로컬에 받아서 파인튜닝을 하고 싶었지만, 그렇게 하려면 {전문: 해석결과} 의 데이터셋이 필요하다. 이 데이터셋이 없을까? 없다... 왜냐면 전문을 한국어 자연어 문장으로 보는 경우가 생각보다 많지 않다.
보통은 이렇게 문단별로 중요 키워드의 값을 본다. 그래서 문장화 하기 위한 전처리 과정이 오래 걸려 파인튜닝을 못해본 것이 아쉽다.

두번째는 데이터가 많이 없다. 물론 전문은 맘만 먹으면 수집 모듈을 만들어서(한국 한정) DB 에 쌓아둘 수 있을 것 같다. 문제는 해석 한국어 라벨링 데이터이다. 항공 도메인은 보안상의 문제로 폐쇄적이여서 항적, 항로와 같은 특정 데이터는 구매해서 사용해야 한다. 그렇기 때문에 한국어로 해석을 한다? 문제를 풀고 답이 맞는지 검사를 해야 하는데 정답지가 부족하다.
다음에 또 AI 를 다룰 수 있는 기회가 생긴다면 그땐 더 딥하고 재밌는 튜닝을 해보고 싶다.
'dev > ai' 카테고리의 다른 글
| [MCP] Claude + IntelliJ IDEA 2025.2.4 (Ultimate Edition) 연동 (0) | 2026.02.23 |
|---|---|
| [Ollama] Ollama 사용기 (1) (0) | 2025.12.29 |